研究概要
論文誌にインパクトファクターがあるように,国際会議にも 暗黙的な格付けがあり,それに応じた論文投稿がなされている. このような国際会議の格付けの自動化の試みは, Conference Ranking と呼ばれている.
本稿では,DBLP からのデータ抽出に関して説明する.
{kind=link}
DBLPを用いた共起関係の抽出
DBLPのデータには,incollection, proceedings, inproceedings, book, article, www, pdthesis, mastertheis などのデータが格納されている. XMLデータファイルは,440MB(2008.2.25日現在)となっているので,処理をするには,データベースにしまってから分析するか,DBLPの検索エンジンに負荷をかけるかをしたほうが良さそう.めんどくさいので,やっつけでパーサーを書いて処理したけど.
DBLPのデータスキーム
DBLPのデータスキームは以下のような形になっている.
- article データ
- inproceedings データ
- proceedings データ
- incollection データ
- pdthesis
- masterthesis
国際会議,研究会などの論文データ.会議名としては 3000.研究者名は,ぐらいのアイテムがあるみたい.
Lecture Notes などのポストプロシーディングのデータ?
DBLPに登録されているデータ
2008.02.27 日現在で,やっつけパーサーでデータをまとめて見た.
- Articleのデータ
- InProceedingsのデータ
- ICRA (7975): ロボット系?
- ISCAS (4491):
- Winter Simulation Conference (4291):
- IJCAI (4130): 人工知能系
- INFOCOM (3961):
- DAC (3610):
- NIPS (3131): 自然言語系?
- Int. CMG Conference(3035) :
- AAAI (3019): 人工知能系
- SAC (2680):
- PDPTA (2578):
- ITC (2510):
- ICIP (2476):
- VLDB (2442): データベース系
- WebNet (2146): Web系?
- Proceedingsのデータ
登録件数の多い国際会議 ( )内は件数.なお,分野に関しては適当に書いている.
このデータは,国際会議名に "(1)" とか,"Vol.1" などがついているデータの成形を行っていない.
会議名の重複に関して
DBLPでは,会議名は省略形で登録されている.ただし,それでは,重複するものが当然存在する.
たとえば,ISWC は,セマンティックWeb関連の国際会議の International Semantic Web Conference があるが,DBLP では ISWC では登録されていない.ISWC は,International Symposium on Wearable Computers として登録されている.同様の例は多々あるので注意が必要である.
特殊文字に関して
XMLデータには,HTML での利用を前提としているのか,ウムラウトなどは HTML用の特殊文字として登録されている.グラフなどに表示する際には,適度に変更する必要がある.
抽出したデータ
著者,会議名の共起データを抽出するにあたり,すべてのデータを使用することは,計算量の点からも難しい.そこで,著者の論文数(thrauth),会議の発表件数(thrconf)を閾値として選別をした.
- thrauth=10, thrconf=100
- 著者リストデータ
- 国際会議リストデータ
- 共起行列データ
- thrauth=15, thrconf=150
- 著者リストデータ
- 国際会議リストデータ
- 共起行列データ
- thrauth=50, thrconf=100
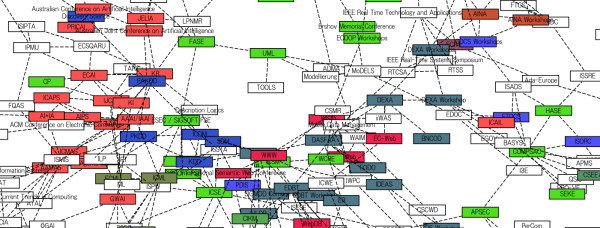
国際会議ネットワークの形成
取得した共起行列のデータを以下の手順でネットワークのデータに変換する.
- カイ二乗値にてデータの補正
- 国際会議名の類似度を,著者ベクトルを特徴ベクトルとしたときのコサイン類似度にて求める.
- 閾値以上の類似度をもつ会議間にリンクをはり,ネットワークデータの形式に変換する.
ノードの色分け
- conference-color2.csv以下のプログラムは,2部グラフマイニングで作成したプログラムを大規模なデータでも扱えるように改良したものである.
- x2_sm.rb
- veccos_sm.rb
- generate_g_data_DBLP.rb
共起頻度データをカイ自乗分布におとしこむためのプログラム.
計算式としては,行i,列j の値 Co_ij を期待値 Co_ij^ex を用いて (Co_ij - C_ij^ex)^2 / C_ij^ex で補正.ただし,Co_ij - Co_ij^ex < 0 のときには,0 としてあつかう.
これにより,共起頻度より表現される各要素の特徴ベクトルの特徴点が強調される.
% ./x2_sm.rb -f [共起頻度データファイル]
pub, auth は,コサイン類似度の計算をするのが行方向(row)か,それと列方向(col)を作成するのか指定している.そのうち row or col に変更する予定でいる
実際には,プログラムをサボっているため,auth = 行 しか有効ではなく,pubはどんな名前でもパスする.
% ./veccos_sm.rb {pub|auth} [共起ベクトルデータファイル名]
本プログラムは,類似度行列のデータから,ネットワークデータ(graphviz形式)を出力する.カラーテーブルは,類似度行列の名前に併せて,各自作成する必要がある.
% ./generate_g_data_DBLP [類似度行列データファイル名] [閾値] [カラーテーブル] > [出力ファイル名]
{kind=link}
{kind=link}
- ファーストネームが省略されている場合があるので,それを取り除く必要があるかも
- 国際会議名も "(1)" とかついているものあるみたいだが,そういうのは省いた方がよいだろうか.
会議間の関係性の定義に,会議C1, C2 の両方に投稿している著者 Ai {i: 1..k} がそれぞれの会議で発表した論文数pi,1 pi,2 を,会議で発表された論文数 s1, s2 で割った値の小さい値の総和で計算しているが,論文あたりの平均著者数 ap1 は 1以上なので,正規化された値としては正しいといえない.
様々な分野でのオブジェクト間の類似性の補完的な手法を提 案する.SimRank を効率的に計算する手法を提案する.