概要
研究者と学会(研究会や国際会議も含める)のWeb上での共起情報をもとにネットワークを構築し,学会や研究者のクラスタリングを試みる.そして,抽出した2部グラフを利用したサービス提供などを考 察する.
Webを用いた2部グラフの抽出
研究者データ,学会データの準備
研究者・学会2部グラフの作成には,まず,研究者名と学会名を準備する必要がある.研究者名に関しては,CiNii や GoogleScholar を用いて共著者情報を利用してクロールする方法や,大学や研究所などの所属者情報を丸ごと利用することが考えられる.学会名に関しても,研究者と同様に手繰り寄せる方法が考えられる.
そこで,以下のデータは,大学のWebページに掲載されている研究者一覧や,日本学術会議に所属する学会などを利用している.
なお,個人名を含むデータに関しては,公開されているデータを編集して人名と思われるデータにまとめているに過ぎないが諸問題が発生する都合なども考え掲載は控える.論文レポジトリなどを活用して個人で作成することを勧めるが,相談には応じるとしておく.
- 研究者名
- MYCOM2007著者名
- 大学教員名
- CiNiiから抽出した著者名
- 学会名
- 日本学術会議に登録されている学会名(1513団体)
- 上記学会名リストからの抜粋(247団体)
- 国内学会誌,研究会名
- 国際会議,海外研究会名(データとして未完成)
- 研究所・大学リスト
- RL-List
人工知能学会が主催している研究会
一応,総合大学とのこと.15学部あるので広くカバーしていると思われる.だが,Web上に乗るような研究活動が少ないのか,共起ヒット件数が非常に少ない教員も多々いる.
某研究者を起点に,共著者名,出版物(研究会,会議,学会)名を利用してクロールしたデータ.ある程度データに偏りがあると思われるが,クロールした著者名に名前のみというデータなども含まれるために,そこそこ広範囲のデータが取得できている様子.
ただし,『社会情報学会』は同名学会が2つ存在するが,別学会として扱うことが難しいために,一つとして扱っている
研(3)リストに含まれる研究者名の一部(30名程度)を利用して,共起Hit件数が0であった学会を抜粋した学会名リスト
研(3)リスト作成時に取得した論文メタデータから Publication を抜粋して作成したリスト.データとして未完成
上のリストと同じ方法で取得したときの英語表記を抜粋したもの
同じアプローチで,大学や研究所のクラスタがつくれるのではないだろうかと思って作成.育英会で免除職としてしている主な機関(ただし,大学以外の学校・地方試験所などは除外)のリストを作成した.
なお,本手法では,研究者と学会との関連性評価をサーチエンジンを利用して行うため,著者に関するWeb上に何かしらの情報が存在する必要がある.そのため,これらの研究者や学会の中には,それらの情報が乏しい場合も存在の対応も必要である.また,同時に,同姓同名問題なども必然的に含まれていることを考慮する必要もある.
また,以下のデータの1行目,1列目はヘッダとなっている.
サーチエンジンを用いた共起情報の取得
松尾らが行っている手法[1] を用いて,学会と研究者の共起情報を取得.ただし,単独Hit件数が少ない(20件以下)研究者名は除外している.
下記は,取得した共起Hit件数の配列(研,学のあとの番号は,前項のデータの順序リスト番号に対応)
- 研(1)─学(2)の共起Hit件数データ[共起データ1](UTF-8)
- 研(2)─学(1)の共起Hit件数データ [共起データ2](UTF-8,64kB)
- 研(3)の一部─学(2)の共起Hit件数データ[共起データ3](UTF-8, 800kB)
研(2)の研究者名と学会名との共起Hit件数のデータ
研(3)の約3000名分の学会名との共起Hit件数のデータ
共起ヒット件数を利用した2部グラフのプロット
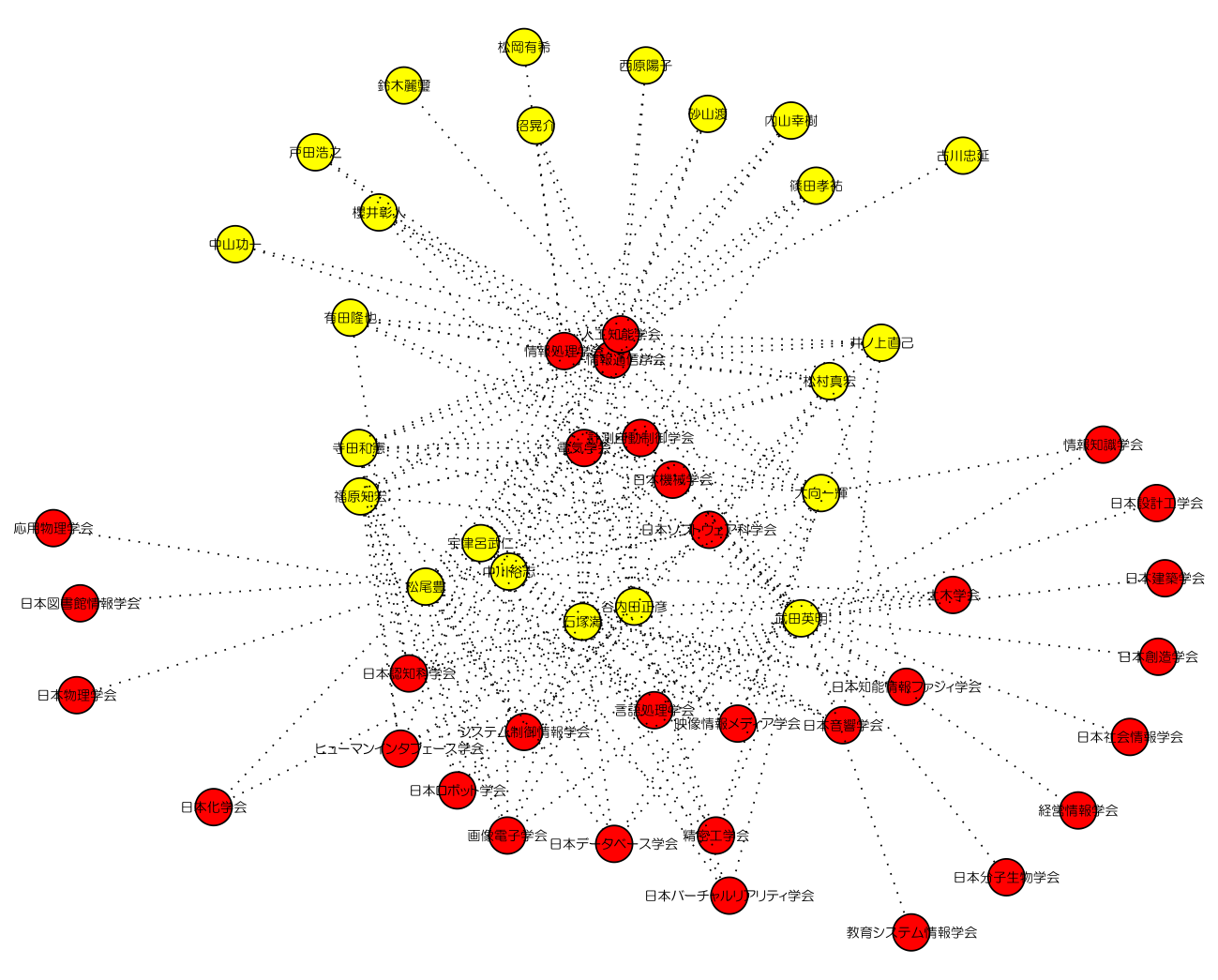
- 共起データ1の2部グラフ(png,420k,neato,閾値=15)
{kind=link}
MYCOMとは人工知能学会主催の若手研究者の集いである.よって,参加者の中心には,人工知能学会・情報処理学会・情報通信学会が集まっていて,中心から少し離れたところに電気学会・計測自動制御学会・があり,そちらに関係している研究者が含まれているであろうと推測される
カイ二乗値によるデータの修正
カイ二乗値とは,偏りの強さを表す値.本研究では,期待値よりも観測値が小さい場合には 0 としている.
- 共起データ1のカイ二乗値
- 共起データ2のカイ二乗値 (UTF-8, 190kB, gz)
- 共起データ3のカイ二乗値
研(2)-学(1)の共起Hit件数データのカイ二乗値
研(3)の約1000名分の学会名との共起Hit件数のデータ
ベクトルコサイン(コサイン類似度)の計算
対象とする二つの要素(x,y)の類似度を計算するためにコサイン類似度(=x・y/|x||y|)を計算する.
類似度を計算する元データとしては 1)共起ヒット件数 2) カイ二乗値による補正データ の2つが考えられる.とりえあず, 2) を使ってネットワーク表示をしてみる
- MYCOM2007: 共起データ1
- 学会間の類似度データ(UTF-8,500kB)
- 大学に所属する研究者: 共起データ2
- CiNii抽出: 共起3データ
- 学会間の類似度データ(UTF-8,500kB)
- 学会間の非類似度データ(UTF-8,500kB):クラスタリング用
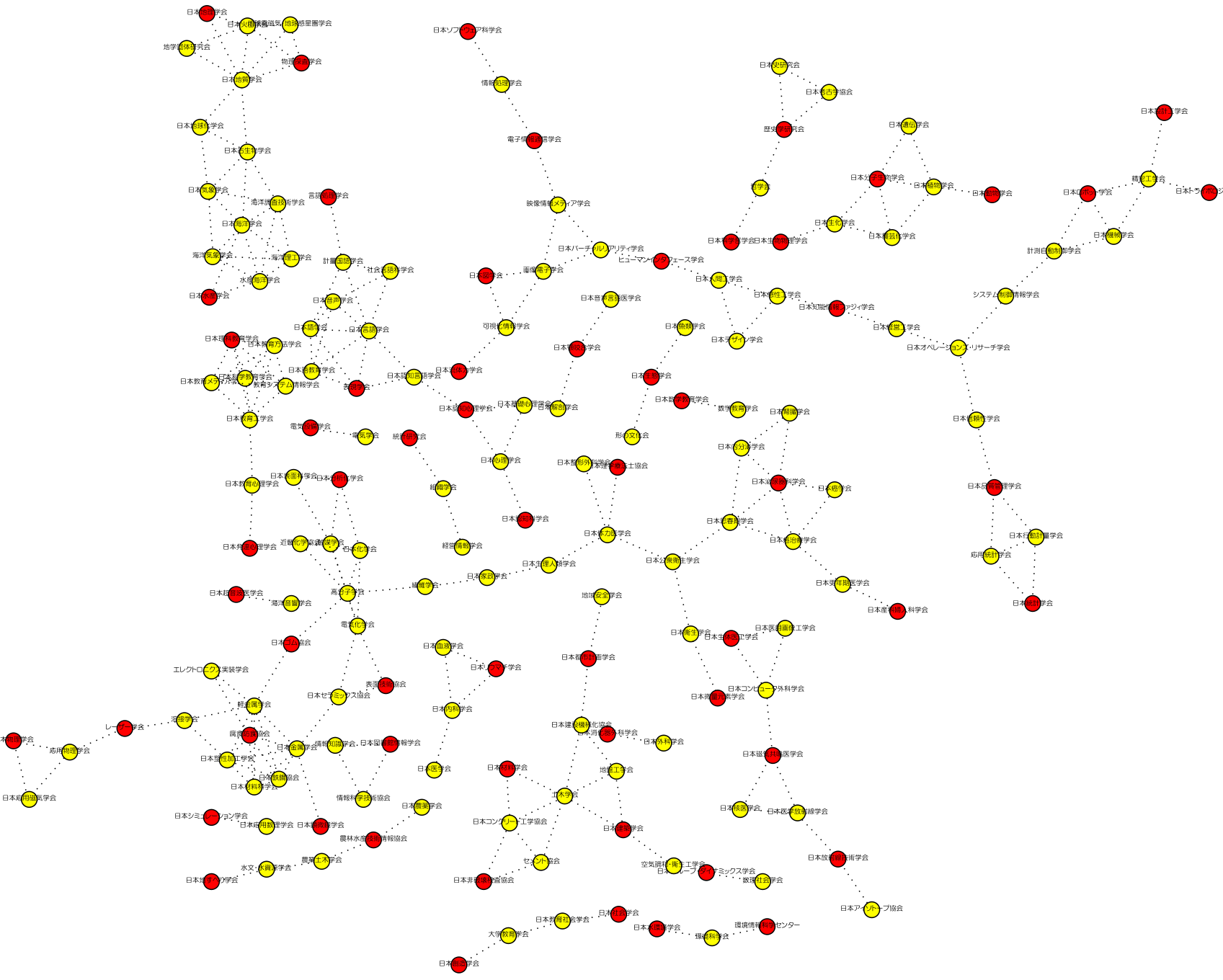
コサイン類似度を用いたネットワーク表示
コサイン類似度のある値を閾値として,その閾値を越えるノード間には関係性があるものとしてネットワークを表示する.
図において,ノードの色が赤と黄色があるが特に意味はない
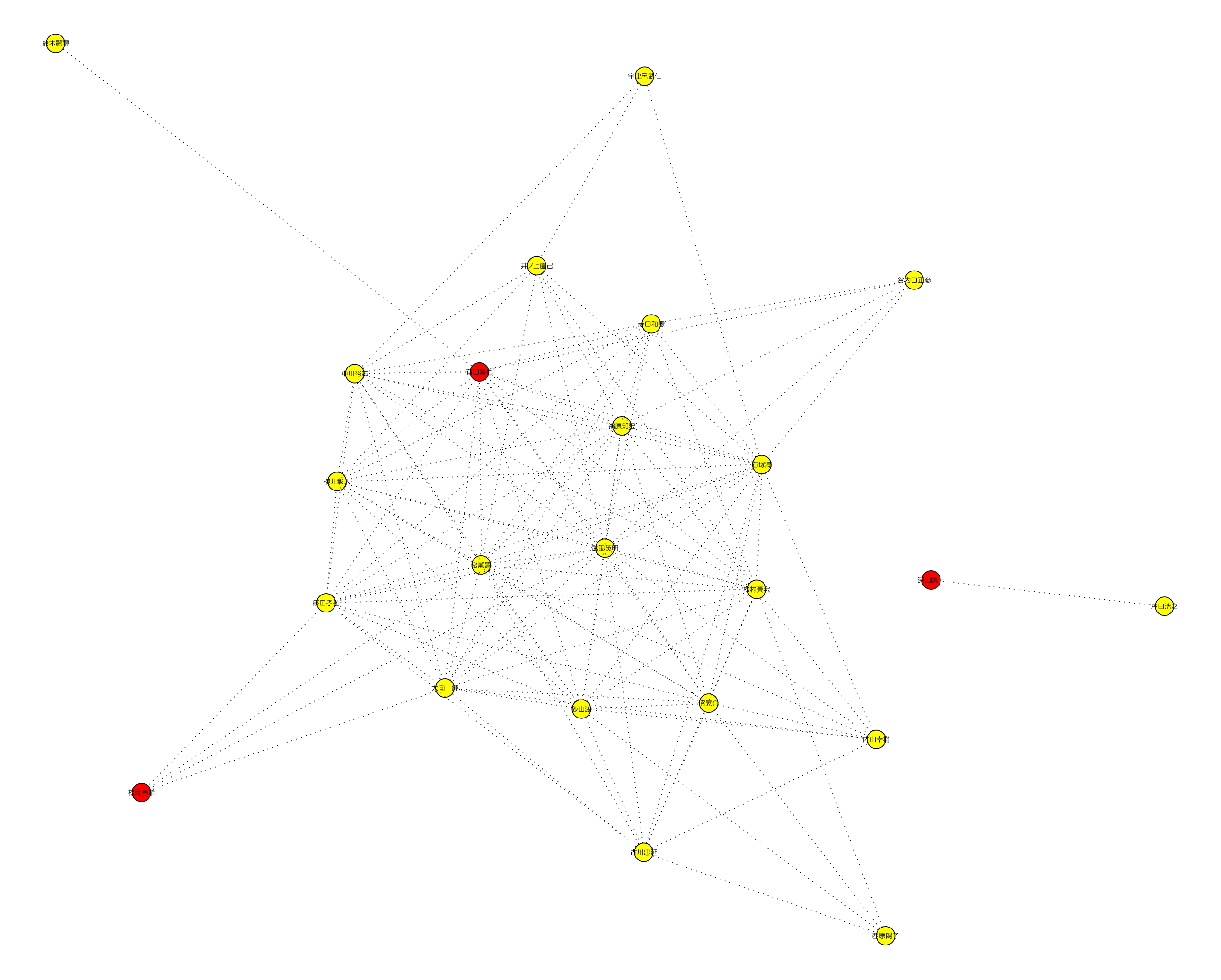
- MYCOM2007: 共起1データ
- 研究者ネットワーク(png,neato,閾値=0.9)
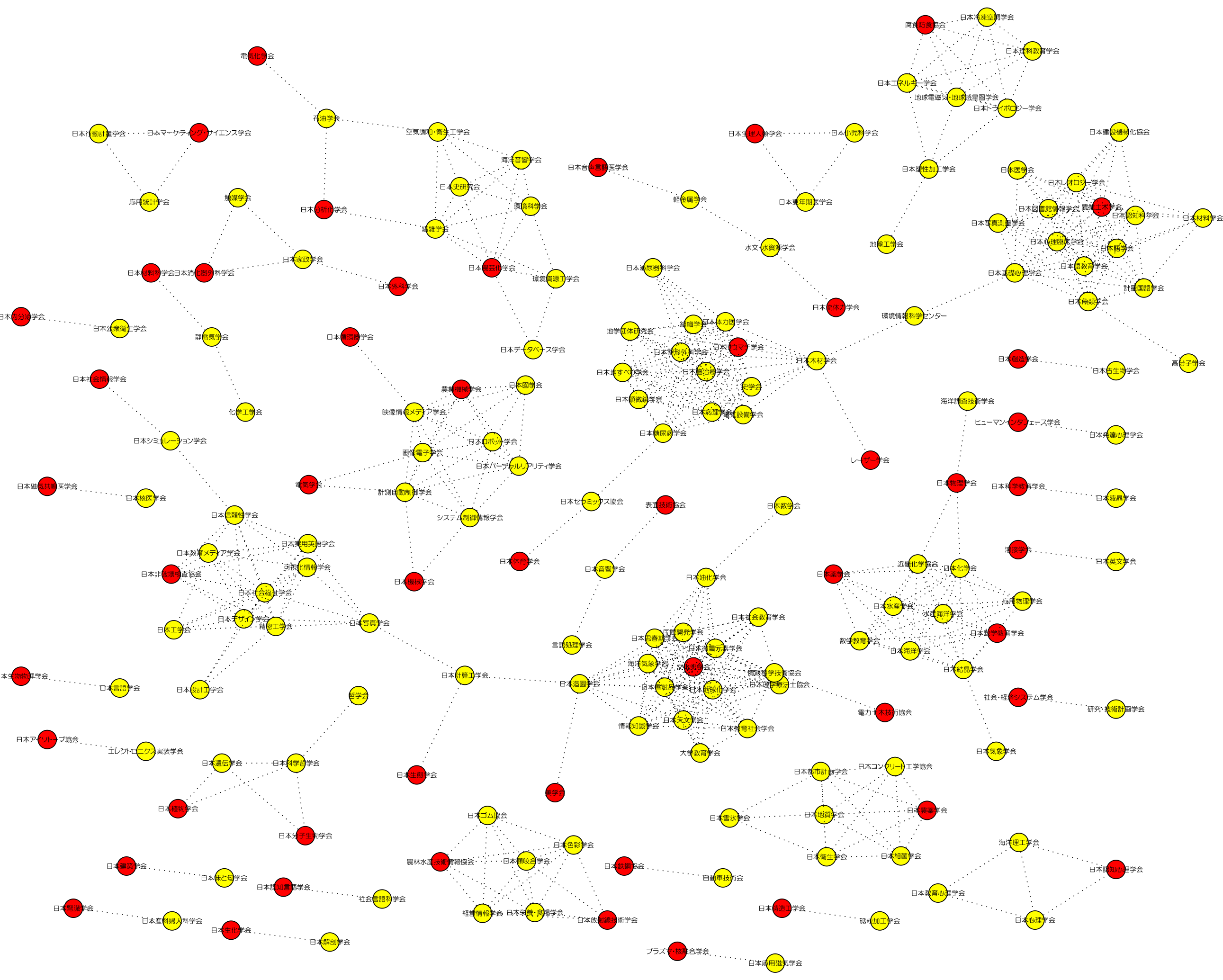
- 学会ネットワーク(png,neato,閾値=0.85)SVG
- 大学に所属する研究者: 共起2データ
- CiNii抽出: 共起3データ
{kind=link}
{kind=link}
{kind=link}
共起ヒット件数からの類似度の場合(png,neato,閾値=0.85)SVG
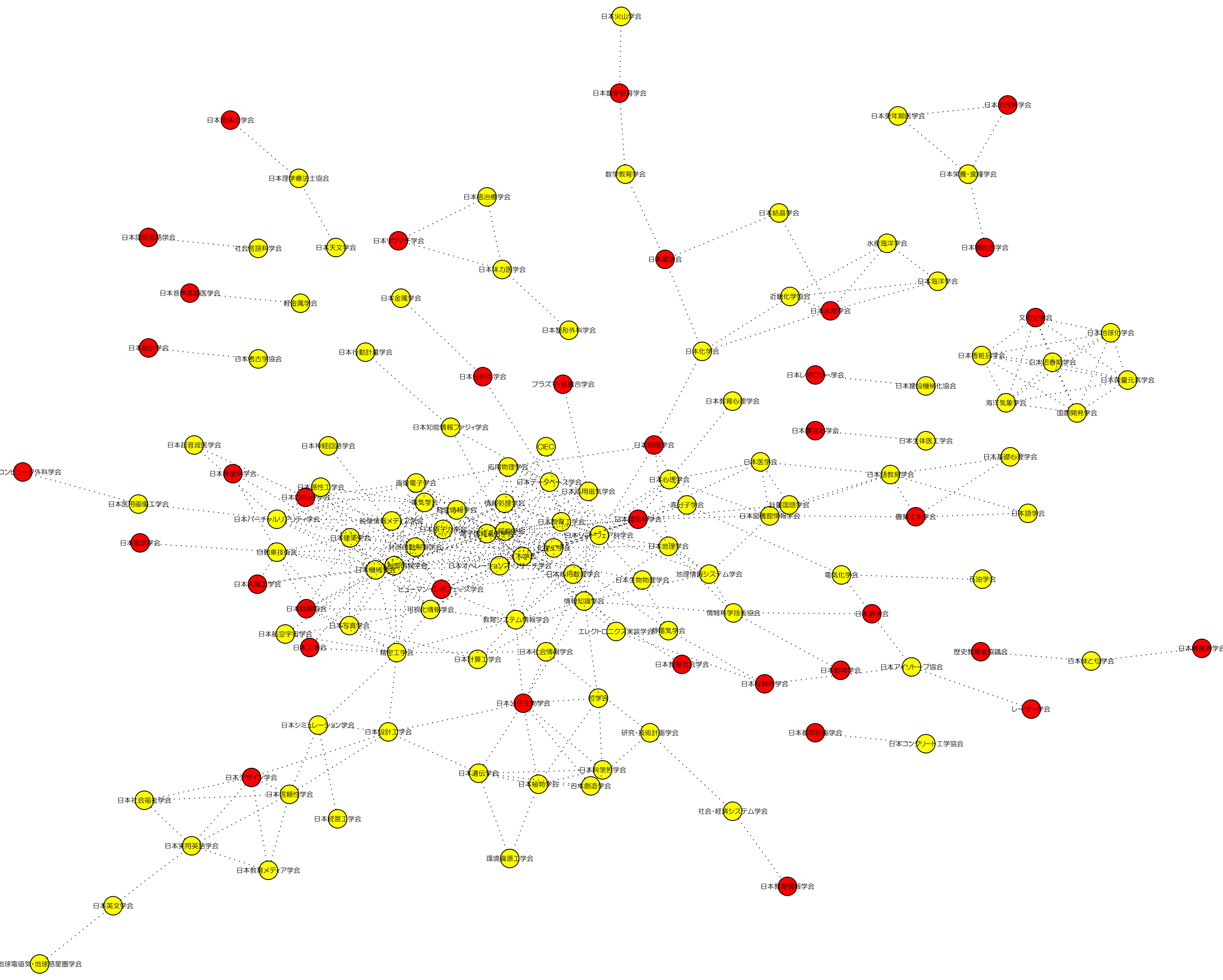{kind=link}
{kind=link}
学会の共起情報を属性値として,教官同士の類似度を計算することで,学群・学科ごとのクラスタができるか検証.学科・学部同士の枠組みがかっちりしているほど,きれいに別れるじゃないかと想像している.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
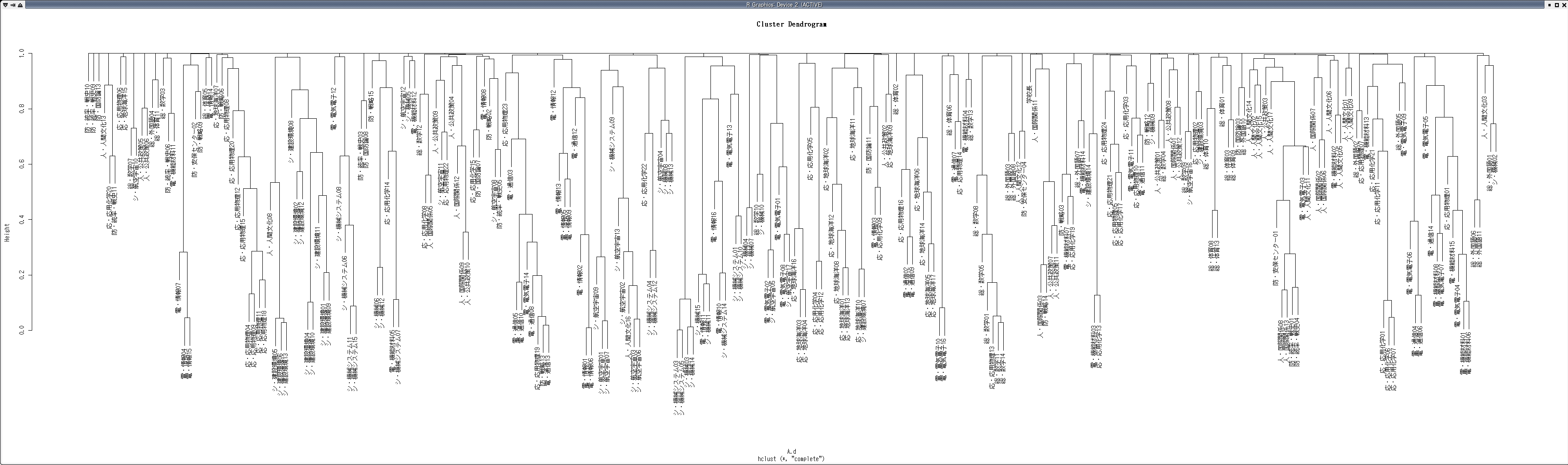
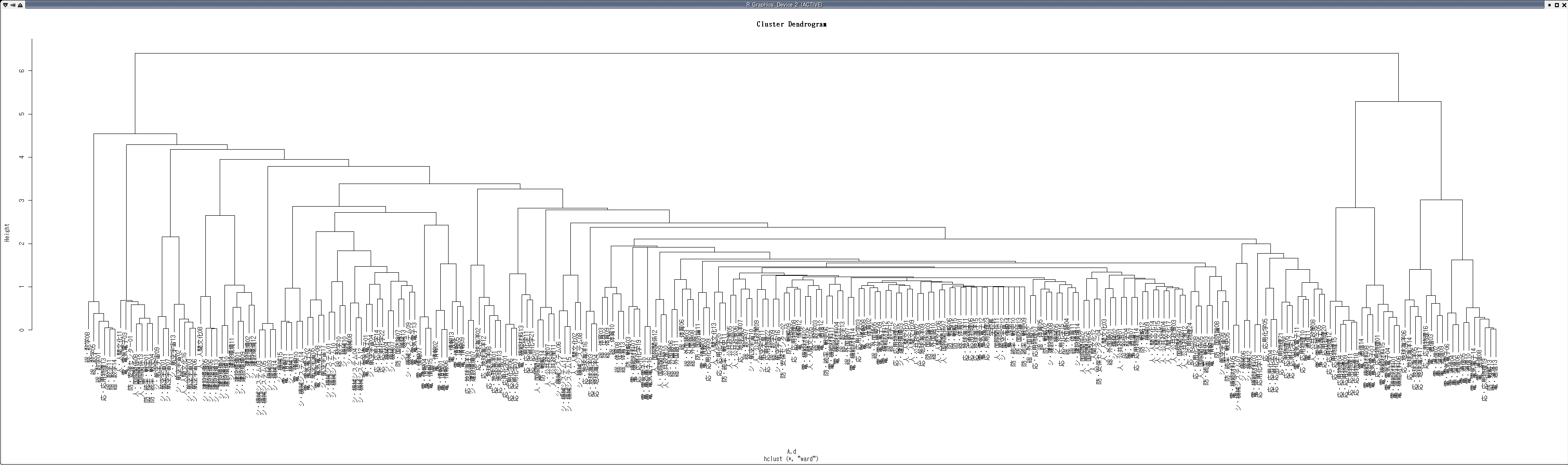
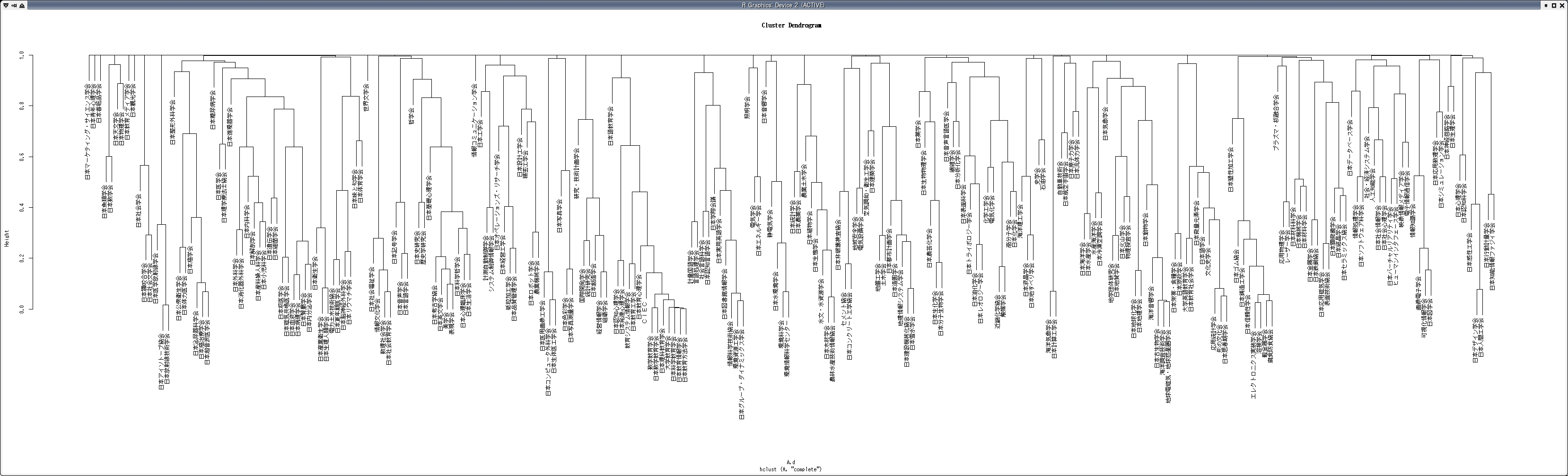
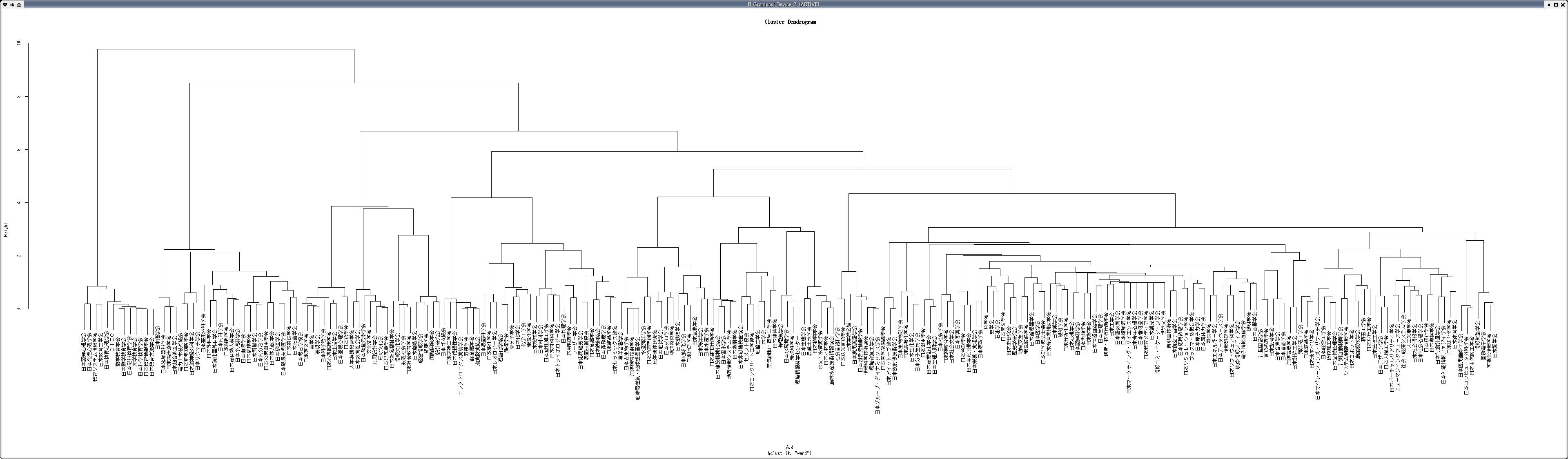
研究者・学会のクラスタリング
クラスタリングは,前項で作成したコサイン類似度を要素間の距離として用いたクラスタリングを行う.クラスタリングは統計解析ソフトである R を用いて計算する
% R
> A <- read.table(データファイル名,header=T,sep=",")
> A.d <- as.dist(A)
> A.hc <- hclust(A.d)
> A.cu <- cutree(A.hc, k=5)
> write.table(A.cu,"出力ファイル名", col.name=F,sep=",")
これで,出力ファイルに名前とクラスタ番号が打たれたテーブルが出力されるはず.詳細は,まず,データをテーブルデータとして読み込み(その際,文字コードに注意が必要).コサイン類似度は既にノード間の距離情報として扱えるので, as.dist にて距離データに変換する.それをもとにクラスターの計算.
- 大学に所属する研究者のクラスタリング結果(樹形図)
- CiNii抽出データ 学会クラスタリング結果(樹形図)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CiNiiデータに関して
ツール・プログラム
下記のツールでは,ファイルのエンコードが utf-8 であることを前提としている.
- 松尾ぐみ 社会ネットワーク抽出ツール?
- カイ二乗値計算プログラム
- x2.rb (Ruby, EUC)
使用方法 % ./x2.rb 共起Hit件数データファイル名 > 出力ファイル名
- veccos.rb (Ruby, EUC)
- veccos_clustering.rb (Ruby, EUC): 非類似度計算プログラム
ノードの類似度を計算する.このプログラムでは,行データは列データを,列データは行データを属性情報(?)として類似度の計算を行っている.つまり,研究者は学会との共起ヒット件数を,学会は研究者の共起ヒット件数をもとに計算する.
使用方法 % ./vecvos.rb 対象ファイル名 > 出力ファイル名
学会の類似度を出力するか,研究者の類似度を出力するかは,プログラムないの変数, $printPub $printAuth を修正する必要がある.なお,プログラムでは,列データを学会名,行データを研究者名と想定している.
また,veccos_clustering.rbは,統計解析ソフト R での使用を想定しており,データ出力のエンコードが euc で,出力される値は非類似度となっている.もとデータが utf-8 で無い場合には,プログラムがエラーとなるので注意が必要
- generate_g_data2.rb (Ruby, EUC)
行列データを一定の閾値をリンクとして graphviz 形式のデータを出力するプログラム.行列データの1行目は,列のヘッダ情報として,1列目は行のヘッダ情報として利用する.そのため (0,0) の部分には "", と空の情報が突っ込まれている必要がある.また,グラフ表示に日本語などマルチバイトを用いる場合には元のデータのエンコードをUTF8する必要がある.
使用方法 % ./generate_g_data2.rb 行列ファイル名 閾値 > 出力ファイル名
- splitsheet.pl (perl, EUC)
表計算ソフトの256列制限に対応して255列ごとに分割するプログラム.ヘッダ部分の行の先頭に "", が必要
使用方法
splitsheet.pl の result_multi.txt の部分を書き換える
出力データ
対象ファイル名に *-N.csv をつけて出力する.すでに存在していると上書きしてしまうので注意が必要