概要
例えば,情報系の学部・学科に重点をおいている,あの大学の特徴は農学部だというように,大学ごとになにかしら特色があるのではないだろうか.そのような特色は,そこに属する研究者など活動にもあらわれ,ひいては Web 上のデータにおいて学会と大学名の共起件数にもなにかしらの影響があると考えられる.
よって,本調査では,2部グラフをWebから抽出する手法を利用して,学会を属性とした大学の類似ネットワークを作成することで,大学ごとの特徴がどこにあるのかを明らかにすることを試みる.そして,それぞれの大学の隣近所となる大学はどこなのか図示してみる.
目的
この調査の目的は,Webから2部グラフを抽出することで,どのような情報が得られ,そして活用が可能であるかを調べることにある.その一つの事例として行ったのが「大学」と「学会」との2部グラフの作成である.よって,現時点では特定の目的に合わせたデータ処理の最適化などは考えていない.
ただし,このような2部グラフを活用することで,受験や就職(転職も含む)の推薦エンジンへの応用などにつながればよいと思っている.
類似度を用いたネットワークの生成
準備
ノードとする大学名ならびに学会名のリストを準備.
- RL-List
育英会で免除職としてしている主な機関(ただし,大学以外の学校・地方試験所などは除外)のリストを作成した.
大学間の類似度の計算
2部グラフを作成したときと同じ手法で行った.以下は,大学と学会の共起件数データである.
ネットワーク図の作成
ネットワーク図は,各大学間のコサイン類似度を用いて行う.ただし,カイ二乗値を用いた補正は行わっていない.その理由としては,カイ二乗による補正を行うと突出したデータがある場合に,少ない数値の値は,他のノード値よりも相対的に大きくてもゼロになってしまうことがあるため,必ずしも適切な類似度が計算できていないように思われるため.なお,これに関して十分な根拠はない.
大学間のネットワークを作成するに辺り,大学を3つのクラスに分ける.
- 国立大学法人 (クラス1)
- ネットワークデータ1+公立大学 (クラス2)
- ネットワークデータ2+私立大学 (クラス3)
- ネットワークデータ1 (graphviz形式)
- ネットワークデータ2 (graphviz形式)
ネットワーク図
- クラス1のネットワーク(neato, png, 205kB) SVG
- クラス1+2のネットワーク (neato, png, 318kB) SVG
- クラス1+2+3のネットワーク (neato, png, 1.2MB) SVG
{kind=link}
{kind=link}
閾値: 0.85, 最低次数: 1 の時のネットワーク図
旧帝国大学を中心とした総合大学のクラスタや医科大学.教育大学あたりはきれいにクラスタとなっていることが見て取れる.
{kind=link}
{kind=link}
旧帝国大学クラスタを含む島は変わらずに,もう一方の島にほとんどの公立大学は属している.主に,看護系の大学や医科大学のクラスタができている.
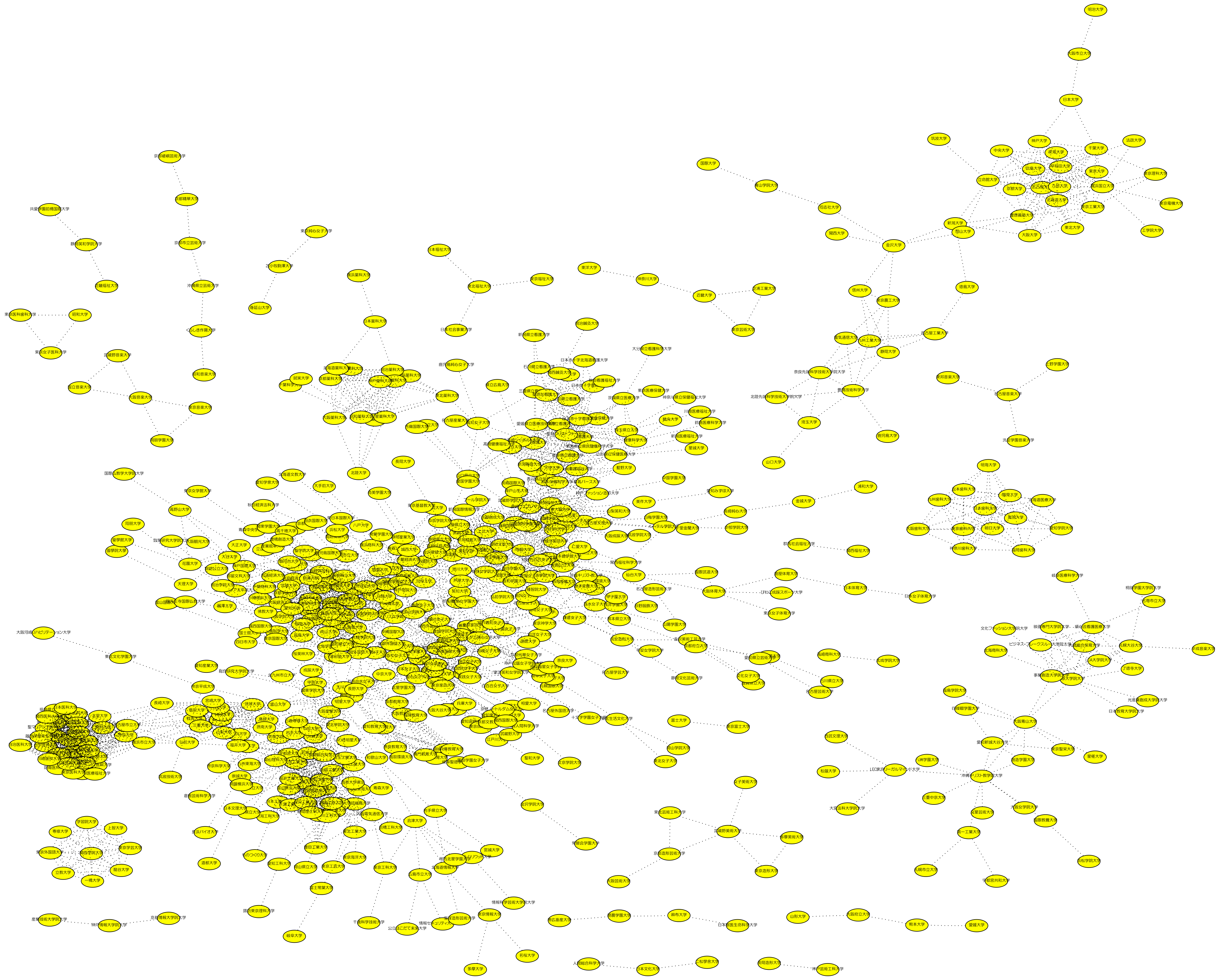{kind=link}
{kind=link}
閾値:0.9, 最低次数:1のネットワーク図
ご近所である大学同士をクラスタリングしてみる
各大学間のコサイン類似度を用いて最長距離法でクラスタリンスした結果を以下に樹形図にて示す.このクラスタリングの作業も,2部グラフのときと同じく統計解析ソフト R を使用して行っている.
- ネットワークデータ1のクラスタリング後の樹形図 (png, 30kB)
- ネットワークデータ2のクラスタリング後の樹形図 (png, 60kB)
- ネットワークデータ3のクラスタリング後の樹形図 (png, 150kB)
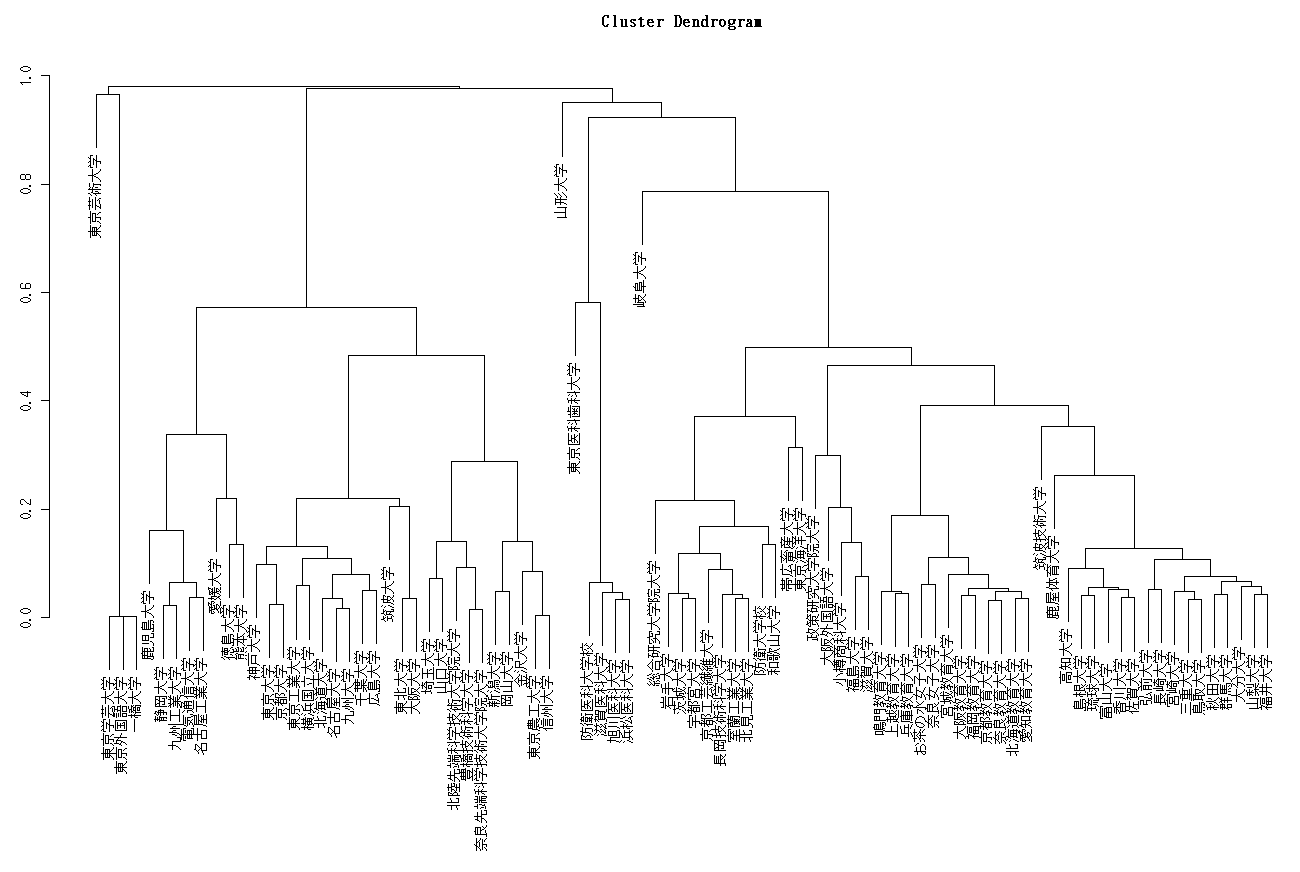{kind=link}
この樹形図から東京芸術大学,山形大学,東京歯科大学,岐阜大学あたりが独自色ある学会活動が行われていると想像されるが具体的にはどのあたろだろうか?岐阜大学だと獣医学科が思いつくが,他の大学にない学部でもないので理由として十分とはいえない.
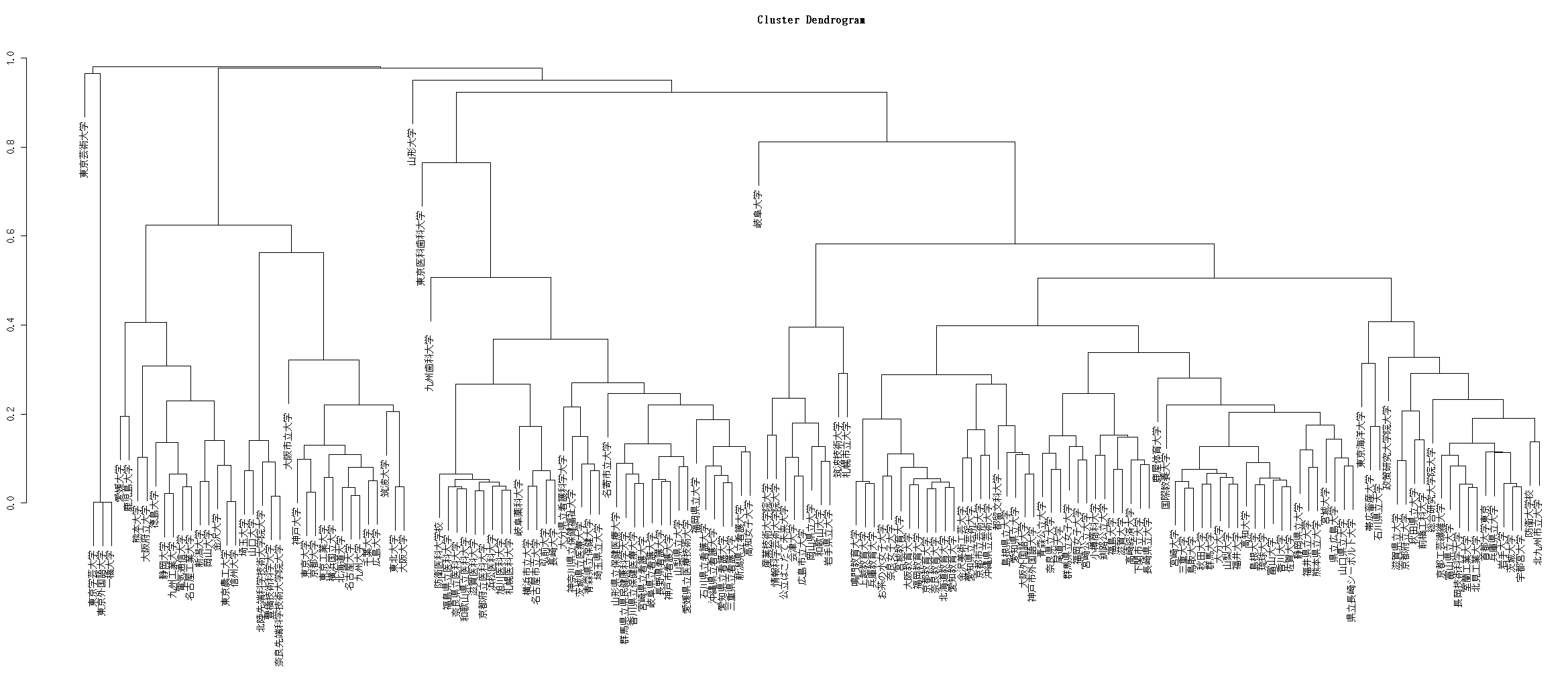{kind=link}
この樹形図でも,医科大学,看護系,情報系大学や教育大学などがはっきりとクラスタリングされていることが分かる.公立大学の中で,大阪私立大学と府立大学が総合大学(?)クラスター側に分類されたが,それに同じ分類がされてもよいのではないかと思われる首都大学東京は,別のクラスタになっている.これはおそらく大学名として新しいものであるために,論文や学会活動に関する WebPage などの量的なものが足りないためではないかと推測され,この辺りが大きく2つのクラスターが形成される理由があるのではないかと考えている.明確な根拠はまったくないが.
現時点(2007/07/18)では,RL-List にあるすべての研究機関にたいしてのデータは取得できていない.
大学特色ネットワークの構造的特徴
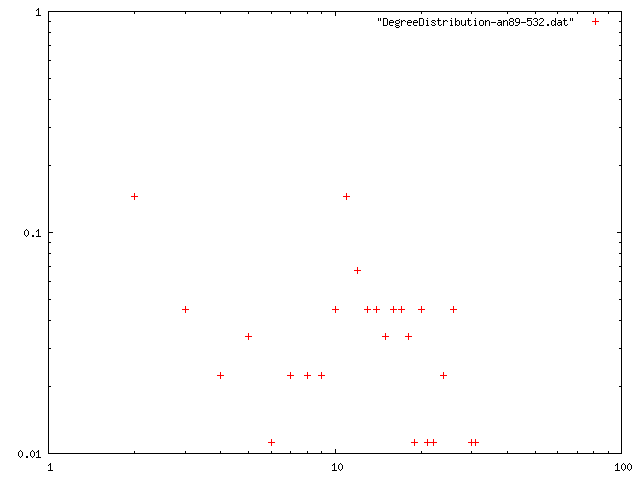
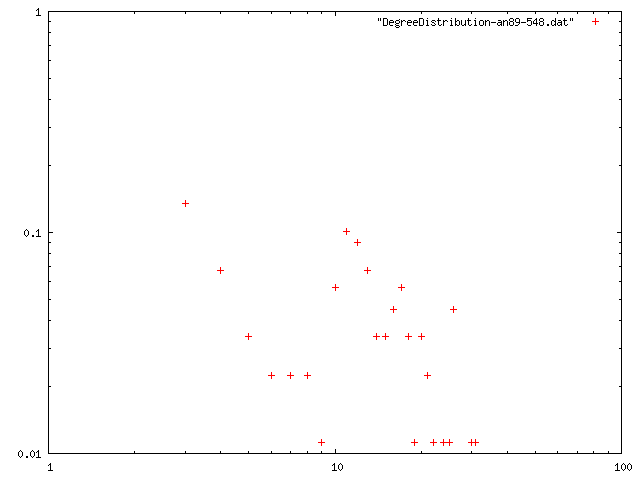
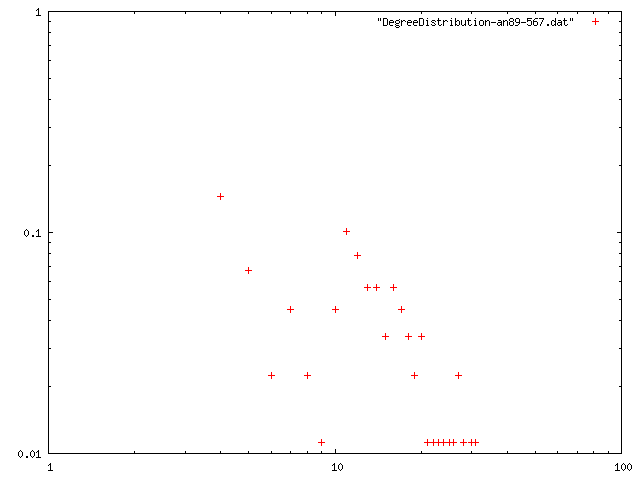
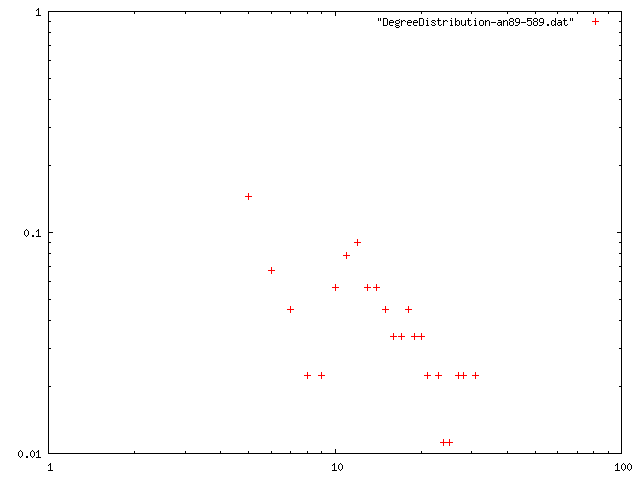
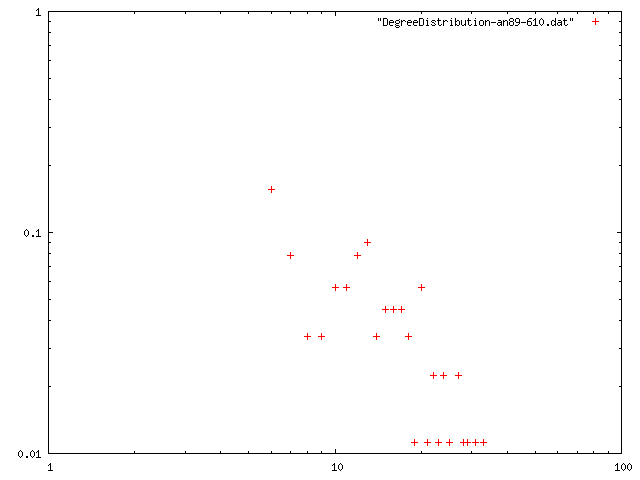
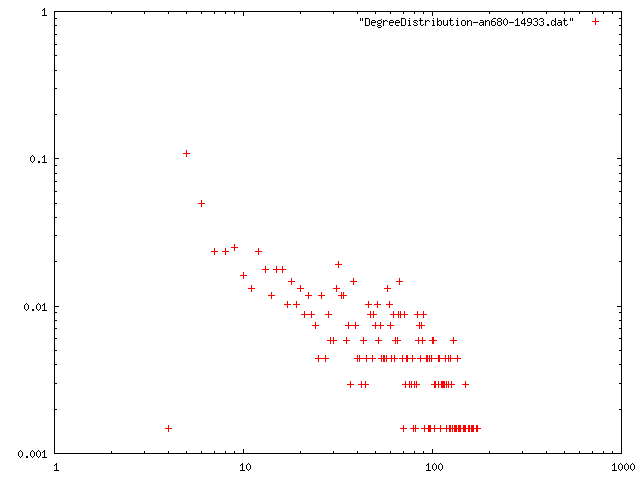
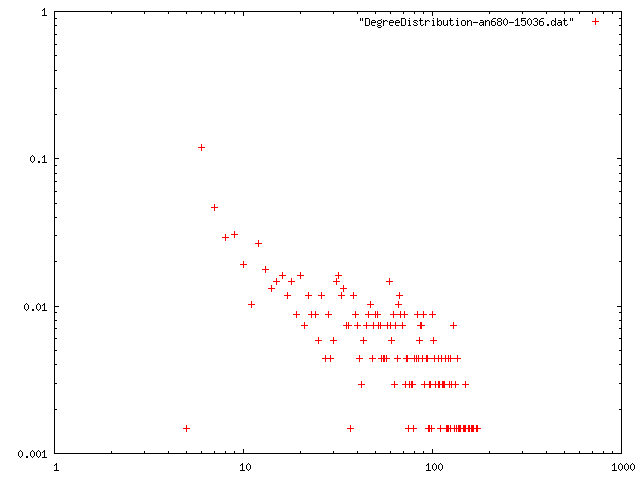
閾値を0.85, 最低次数を増やしたときのネットワークの構造的特徴量を計算.平均距離は,おそらく最大クラスターの距離を計算している.
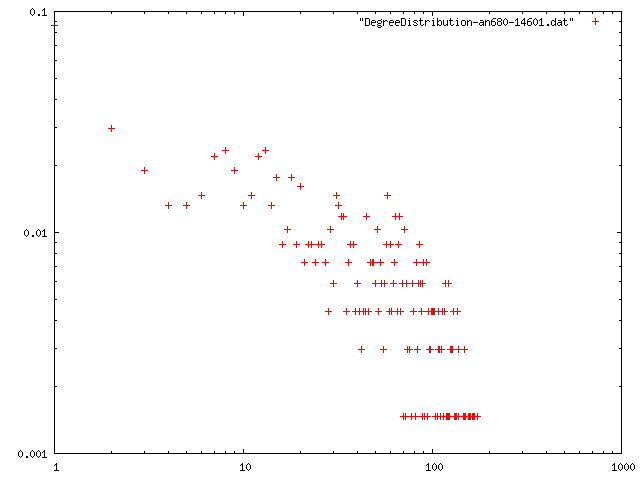
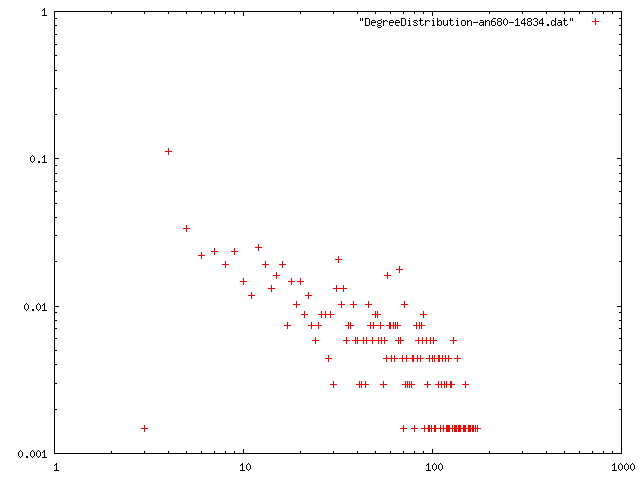
ネットワークデータ1
| 最小次数 | 次数平均 | 平均距離 | クラスタリング係数 | 直径 | 次数分布 |
| 1 | 11.707 | 1.13202 | 0.676145 | 8 | png |
| 2 | 11.955 | 4.43565 | 0.754669 | 12 | png |
| 3 | 12.3146 | 4.02451 | 0.725079 | 10 | png |
| 4 | 12.742 | 3.73212 | 0.732982 | 10 | png |
| 5 | 13.235 | 3.61006 | 0.707653 | 9 | png |
| 5 | 13.279 | 3.37921 | 0.716999 | 8 | png |
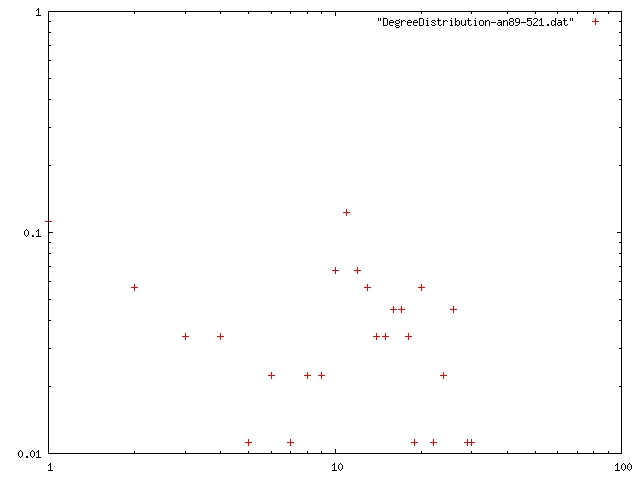{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
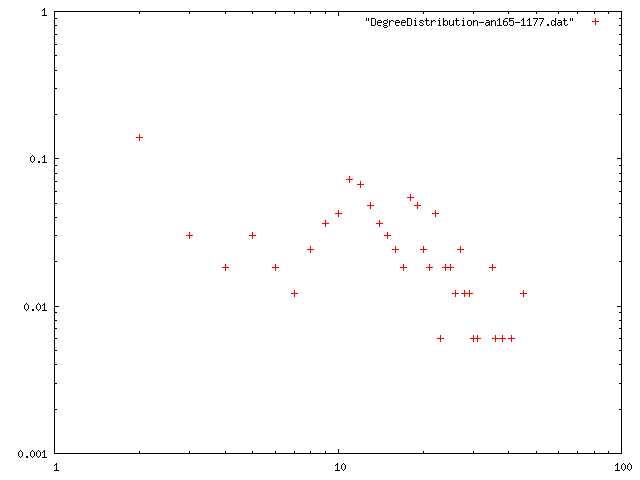
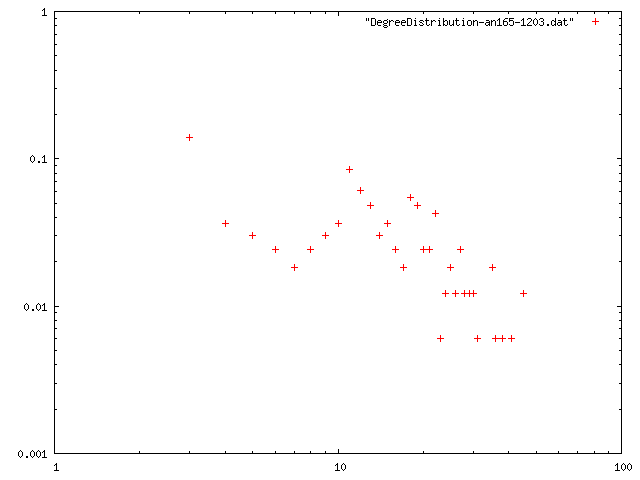
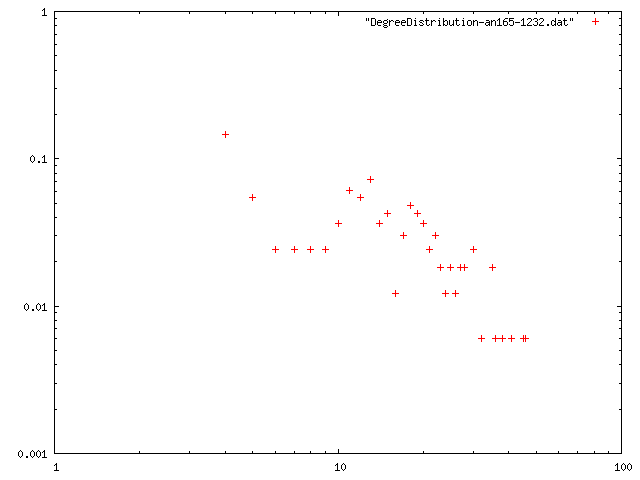
ネットワークデータ2
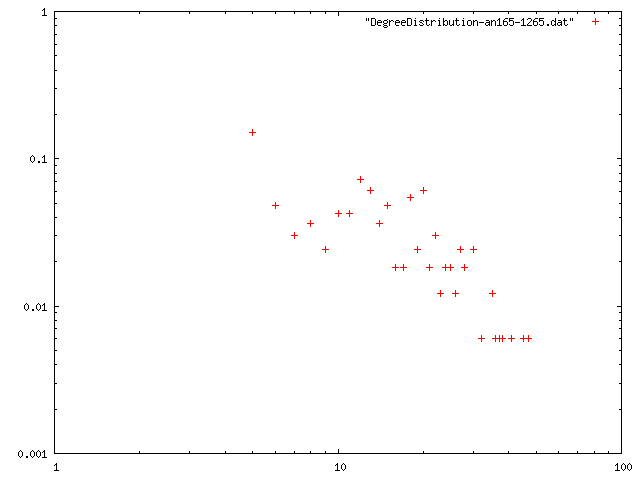
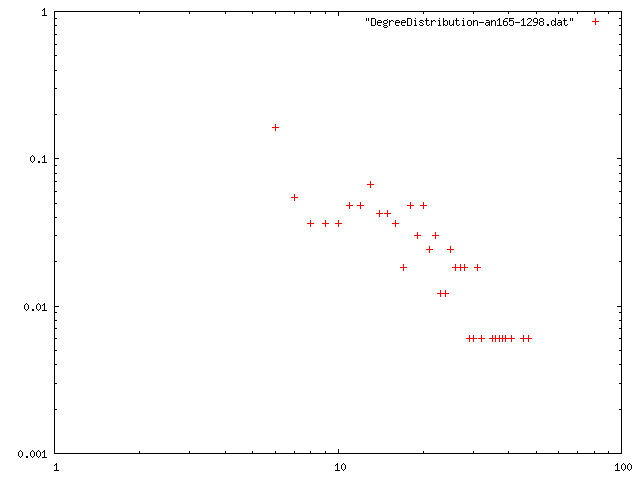
ノード数165のネットワーク
| 最小次数 | 次数平均 | 平均距離 | クラスタリング係数 | 直径 | 次数分布 |
| 1 | 14.048 | 1.72099 | 0.623556 | 7 | png |
| 2 | 14.267 | 1.66733 | 0.690496 | 6 | png |
| 3 | 14.582 | 4.14841 | 0.681947 | 11 | png |
| 4 | 14.933 | 3.81633 | 0.67427 | 10 | png |
| 5 | 15.333 | 3.6861 | 0.667872 | 10 | png |
| 6 | 15.733 | 3.51493 | 0.673944 | 9 | png |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}